



How NVIDIA Conversational AI Could Impact the Metaverse and Why It Matters
NVIDIA researchers shared some of their latest work on speech synthesis and recognition at the Interspeech 2021 Conference in early September 2021. NVIDIA’s goal for speech synthesis and recognition technologies is what they call Conversational AI. Conversational AI is a voice assistant that can engage in human-like dialogue, capturing context and providing intelligent responses. The stunning advances demonstrated at Interspeech will almost certainly bring dramatic changes to the way people interact with technology in both real and virtual worlds.
Capabilities of NVIDIA Conversational AI
A stark demonstration of Conversational AI’s capabilities appeared during the 2021 NVIDIA annual conference. NVIDIA’s CEO, Jensen Huang, gave the keynote address from his kitchen via video. Event producers slipped a virtual Huang into the keynote, and no one noticed the difference even though virtual Huang’s voice and image were computer-generated.
Another impressive example of Conversational AI is introduced in the NVIDIA I Am AI informational video series. The pleasing voice of the narrator in the series is computer-generated.
When you combine Conversational AI with advanced real-time graphics processing, one of the things you get is Vid2Vid Cameo.
Imagine having a rough night and rolling out of bed late for an important video call. You want to present the best image of yourself, and with Cameo, you can. You upload a photograph of yourself dressed in your best business attire. Cameo uses the photo to generate a video image of you. Cameo uses your actual image from your computer’s camera and maps your facial expressions to the virtual you during your call. Your colleagues see and hear the best you, even though the real you is dressed in a bathrobe and hasn’t combed her hair in three days.
Vid2Vid Cameo brings together Conversational AI with advanced real-time graphics processing to help create a life-like virtual person.
How NVIDIA Conversational AI Works
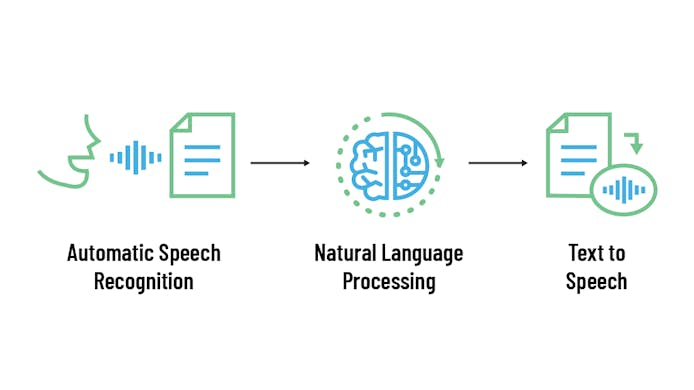
To create a conversation indistinguishable from interacting with a human, you must complete three steps.
- The AI must recognize the words you are using, known as Automatic Speech Recognition.
- The AI must understand what the words mean, known as Natural Language Understanding.
- The AI must respond in a way that makes sense and sounds like a human, known as Speech Synthesis.

Automatic Speech Recognition
Automatic Speech Recognition takes a voice and turns it into text. But converting voice into text is more complicated than it seems on the surface. It is more than matching a sound to a word in a database. The AI must separate the voice from background noise, which may be other voices. It needs to recognize the same word in different accents and tones of voice. The AI also needs to recognize specialized words such as industry-specific jargon and slang.
AIs accomplish these tasks by training rather than coding. The more times an AI hears a word, the more accurately it recognizes it. When you read voicemail transcribed on your phone, you get an idea of how challenging it can be to train an AI to recognize words like a human would.
In human speech, context matters—where we speak, why we speak, who our audience is, what our goal is matters. In short, speech is complex and complicated. -- “Speech Recognition is hard,” Towards Data Science
Natural Language Understanding
Natural Language Understanding (NLU) takes text as input, understands context and intent, and then generates an intelligent response. NLU is the core of applications such as a virtual customer service agent or a realistic non-player character in a game.
The best NLU applications, such as those demonstrated by NVIDIA, understand the words spoken in a moment and how those words fit into the conversation based on previous conversations.
Natural language understanding (NLU) is the comprehension by computers of the structure and meaning of human language, allowing users to interact with the computer using natural sentences. -- Gartner
Speech Synthesis
NVIDIA has developed a breakthrough in speech synthesis. This breakthrough results from a significant change in perspective. Rather than focusing on speech, NVIDIA researchers have begun to view speech as music. Like speech, music has a flow with changes in inflection in timbre, tone, and pacing. These qualities make human speech feel natural when so many generated voices for your navigation system, or your virtual assistant seem rigid. One by-product of starting from a musical perspective is that Conversational AI can sing. In other words, if you ever wanted to sing like Justin Timberlake or Cher, you can do so with Conversational AI.

It is possible to train the NVIDIA AI using one of two methods.
For the first method, the AI receives samples of a human speaking. With enough examples, the AI learns to mimic the voice. The AI can then take any text and speak it in the human voice. The result is that you get driving directions from your navigation system that sound like Sean Connery.
For the second method, the AI listens to the desired output spoken by a human. The AI can then reproduce the conversation in a different voice while preserving the pacing and tone of the original speaker. The result of this second method is that a Conversational AI-enabled karaoke machine could enable you to sing in Luciano Pavarotti’s voice.
The Potential for Voice AI
NVIDIA Conversational AI seems to have developed to a point where it will be challenging to determine if you are dealing with a human or a machine. The applications of this technology are where things get interesting.
Suppose you are playing an immersive multiplayer game like Fortnite. Today you can speak to other players inside the game. Imagine, however, a future in which you could purchase the voice of R. Lee Emery, who played the drill sergeant in Full Metal Jacket. The other players would hear your words in Emery’s voice with your tone, inflection, and excitement.

Imagine a translation app on your phone that you could speak to in English, and it would repeat your words in French or Chinese, or Hindi in your voice. Or, if you are in an online business meeting, the translation would happen in real-time, and the people you are speaking to in Jordan or Croatia would hear your voice in their language while you listen to their voices in English. The concept of instant translation using AI is similar to the universal translator from Star Trek.

Imagine a world where you speak to international business associates in English, and they instantly hear your voice in their native languages. Your associates respond in their native languages, and you listen to their words instantly in English.
Imagine you have purchased an electronic device from a manufacturer who makes dozens of variations. You are having trouble using your device. Would you rather call customer service and speak to a real person who may not have ever seen your specific device and follows a set script to help you troubleshoot? Or perhaps you prefer a virtual agent that sounds and responds like a human but has instant access to user instructions for your specific device? The virtual agent analyzes the discussions of every other customer who has called about the same device—and is available 24/7 in any language.

Each of these scenarios is technically feasible today. Tomorrow, in the metaverse, Conversational AI is likely to change your experience drastically. Imagine you enter the metaverse and arrive in a virtual town square. Where should you go, and what do you do to get started?
Your guide appears beside you and helps you get started. You would not be able to tell if the guide represents a real person, just as you are, or if the guide is entirely computer-generated. You would be able to speak to all the people you meet in the metaverse regardless of what language they speak. You would be able to alter your environment or change virtual locations simply by asking. You enter a virtual store and describe what you want to purchase. You look at the products available and narrow down your choices by saying things like, “I want this in blue.” Once you purchase your item, you receive it.
The Challenges for Voice AI
With the advance of graphics processing units (GPUs) and AI models that continuously improve, the potential for voice AI is limitless. However, that potential becomes dramatically limited by the public internet.

In natural conversation, the gap between responses is about 300ms. For a conversation with an AI to seem natural, when you speak to the AI, it must complete all three steps outlined above within 300ms. It is possible to complete those steps within the allotted time on a properly configured, moderately sized computer available on any major cloud platform. The problem is that transmitting the response back to your computer can often take from 100 to 500ms.
The network transmission time eats up all the time required for natural speech, even without the processing. To deliver the full potential of voice AI, it needs to run on a better network.
For a conversation with an AI to seem natural, when you speak to the AI, it must complete all three steps outlined above within 300ms. The 300ms requirement can only happen on a network designed for real-time.
Voice AI Needs a Better Network
Subspace is the network solution for real-time applications. We provide real-time users with the fastest, most reliable, and secure paths for internet applications.
Leveraging our servers distributed worldwide and our proprietary AI, we weather map the internet to continuously route users on the quickest path possible to and from any destination in the world. On Subspace, we reduce lag by 80% and increase stability by 99%. Subspace provides the perfect environment to unleash the potential of Conversational AI.
We deliver real-time connectivity from anywhere to anywhere with no client-side installation required.
Unleash the potential of Conversational AI today on Subspace. Every Millisecond Counts!



