Ideal settings for TCP (transmission control protocol) and UDP (user datagram protocol) performance vary depending on network settings and requirements. However, there are some primary considerations. In this post, we’ll explore core principles of communications tuning and provide some helpful tips. We’ll also discuss why the communications-I/O characteristics of an application should be considered for optimization.
Throughput or Memory?
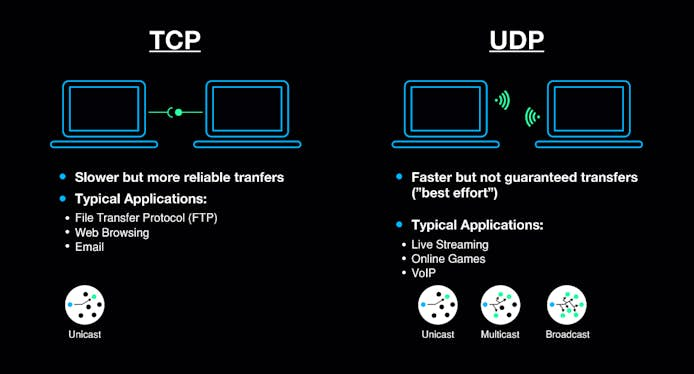
TCP and UDP were designed to do the same thing in two different ways, the former being designed for stability (never lose a packet), and the latter for speed. Depending on which you need to optimize for, there are a number of factors to take into account. The first question, of course, is about priorities. How much loss is tolerable in exchange for higher throughput?
With TCP, your application will effectively stop all transfers in order to recover the lost segment, whereas UDP expects the application to either ignore the loss, or just queue up the lost segment while all the other segments continue.
If you’re still debating about which protocol is best for your use case, you may want to take a look at our excellent primer on TCP and UDP.


TCP Performance
Three related factors affect TCP performance: latency or round trip time, buffer/window size, and packet loss.
Latency is the amount of time it takes for a packet to go to its destination and return to the sender, which is why it’s sometimes called round trip time (RTT). Buffer size determines the amount of data the kernel will keep in buffers for connections. The window size reflects how much data can be inflight between two hosts.
The amount of available bandwidth multiplied by latency, plus a too-small-window equals lower performance. In other words, if the window is smaller than the available amount of bandwidth, the sender will send a full window of data, then wait for acknowledgement, resulting in lower performance.
The problem is helped in part by TCP buffer autotuning, which makes the kernel the right size for the connection. Without autotuning, the system-global parameters must be set for optimization, or the application has to know the underlying network and set buffers currently.
And, the most important and most complicated factor affecting TCP performance is packet loss. When TCP encounters packet loss, it reduces the sender’s estimate of the window and sends less data. Then, it slowly ramps up again in case the loss was temporary.
Loss requires recovery in TCP. The recovery is the ramping up of the send rate after packet loss. As the time necessary for recovery goes up—which depends on latency—the round trip time goes up, too. In most frameworks, there are algorithm options that can assist with this recovery, but the performance is still often suboptimal.
But that’s not all! Undersized buffers in routers, switches, and firewalls all affect TCP latency also. Large buffer windows are necessary when latency is high, as in over 10 milliseconds. TCP sends a lot of data at once when the window is large, regardless of what the network card is configured for. If the network card is configured for a larger link speed than the window, there can be buffering and queuing problems along the path, causing packet loss.
With low latency connections, users are not likely to even notice TCP window issues. TCP can recover quickly when problems are caused by random errors such as long cable length or dirty fiber, and small buffers in the path don’t usually cause loss in low latency connections. But, when information needs to travel a long way, there could be a very noticeable problem with performance, and a random error could cause TCP to remain in recovery mode with a small window.
UDP Performance
UDP tuning is a bit more straightforward, but there are still some essential considerations, including:
- Requests and responses—when they are fixed-size and fit into one datagram, UDP is the best choice
- Packet size—set the buffer’s packet header size to the maximum transmission unit (MTU) size (see the note below about wasted space)
- Buffer size—in UDP, buffer size isn’t related to round trip time like it is in TCP, and defaults may need to be changed
- Socket buffer size—in general, larger socket buffer sizes will distribute faster, at the expense of using more memory
Optimizing
The general principles for maximizing throughput include request-response protocols, streaming optimization, and minimizing memory.
To maximize the transactions per second, use the smallest possible messages. For the maximum bytes per second, use messages that are at least 1000 bytes and equal to or just less than a multiple of 4096 bytes. Also, use optimum write sizes to allow for standard IP and UDP headers, especially when requests or responses are variable in length. Consider implementing the TCP_NODELAY option.
For streaming optimization, pay special attention to write sizes. They should be in multiples of 4096 bytes. That’s a more efficient way to use the 4096-clusters that are used for larger bytes. Consider the fact that writing 936 bytes would give you 3160 bytes of wasted space per write. The application could hit the udp_recvspace default value of 655366 with just 16 writes totaling 14967 bytes of data.
Whether you’re using TCP or UDP, the result is often wasteful. With TCP, it’s a waste of memory and time, and with UDP, it’s a waste of memory.
Avoid delays and throughput reductions in TCP by setting a maximum segment size (MSS). The MSS depends on whether the systems are using the same network or if one is on a remote network. Local networks don’t require MSS tuning.
The default for a remote network is an MSS of 512 bytes, based on the fact that all IP routers support an MTU of at least 576 bytes. The default setting is good for most uses but can be restrictive on private internets.
Further, the optimal MSS is the smallest MTU of the networks being traversed between the source and the destination. The quantity changes, though, and TCP doesn’t have a way to account for those changes, which is why there’s a conservative default of 512 bytes. You can also enable Path MTU Discovery. Here’s a PMTU command line reference if you want to learn about enabling/disabling on multiple platforms.
In some situations, such as using a VPN into a LAN or running on the wild world of the public internet, there are many factors outside your control. With latency, jitter, and packet loss to contend with, there was only so much you could do—until now.
The Subspace network can significantly reduce your need for tuning while giving your applications and configuration a considerable boost. A simple API call to our global IP level proxy and PacketAccelerator will accelerate and stabilize your real-time connections.