



TL;DR
Today’s internet is no longer “good enough” to support the surging demand from real-time applications. We need to address the impact of global latency and work to improve it by implementing a better, more accurate set of metrics and improved solutions.
Estimated read time: 10 minutes
The way we operate online has fundamentally changed.
Today’s users of real-time applications have become accustomed to a high level of performance.
The problem is, the internet was not built to handle the surging demands of real-time applications. The internet as we know it is strung loosely together for reliability and delivery, not performance optimization.
In a world where remote work and multiplayer gaming are the new normal, the internet is no longer “good enough.”
Understanding the scope and scale of global latency is one of the keys to meeting the true needs of our real-time internet.
Let’s explore this together to learn how we, as a collective, can battle the problem of latency on a global scale.
The #1 Thing Developers Misunderstand About Global Latency
There has been an ongoing debate in the database community about the scalability and performance of SQL vs. NoSQL.
The former is used for highly structured and unchanging data, while the latter is praised for its flexibility, speed, and scalability.

Both, of course, have their own merits and use cases.
In 2021 and beyond, the same conversation has to be had as it pertains to networking, and more importantly, the scalability of our approach to network performance.
The main problem today is that developers don’t see use cases, request-response, or information flow as being distinct.
Furthermore, everyone tends to look at the problem of global latency from a storage and compute lens, often leaving out consideration of the network itself.
This crucial missing piece plagues real-time applications and user experience on a global scale.
To solve the ever-present problem of global latency in today’s real-time world, we need to look holistically at storage, computing, and the network.
When we can solve for all three of these critical components, we can make real progress in solving global latency problems.
Defining The Problem: Then vs. Now
Let’s take a trip back in time.
The year is 2006. You are on your Motorola Razr (the greatest cell phone ever) chatting away with your best friend. Then it begins…
“Can you hear me now?”
“Are you still there?”
Then comes the choppy voice on the other end.
Finally, when you are at your peak level of irritation, the call drops completely.
Those were the early days of global latency, a problem many of you will remember all too well.

Fast forward to 2021, the problem of global latency remains, but the use case has changed.
Now, we see this issue magnified in real-time applications like Zoom.
You all know the situation:
- Furiously adjusting microphone settings when experiencing acoustic feedback
- Closing and reopening sessions when your guests or clients freeze
- People talking over one another other when latency issues cause real-time delays
It is equally, if not more frustrating, than when latency ruined your cell phone calls fifteen years ago.
In a world where users have become accustomed to a certain level of fluidity, these poor user experiences have become increasingly unacceptable, even if we are talking about a few seconds of interruption.
As developers, we know this and have implemented what we call “optimistic rendering” to help provide a more instantaneous and enjoyable experience for users.
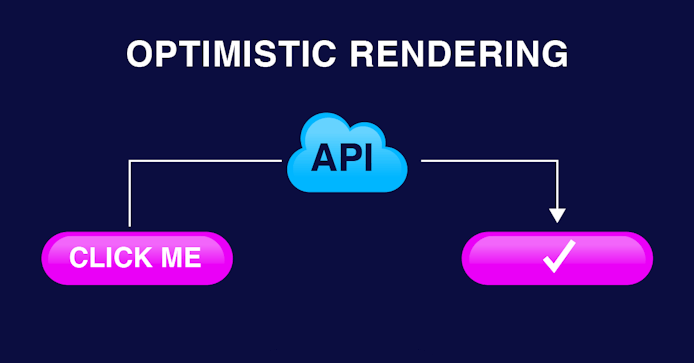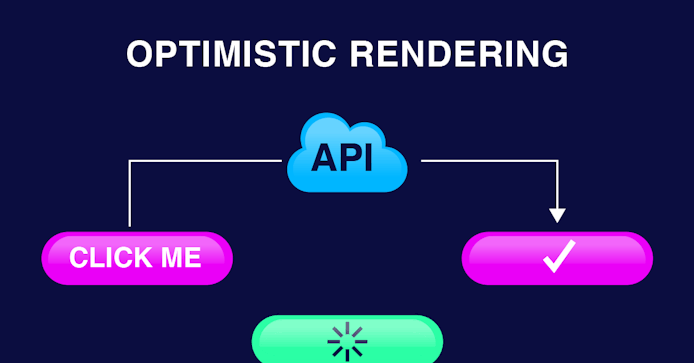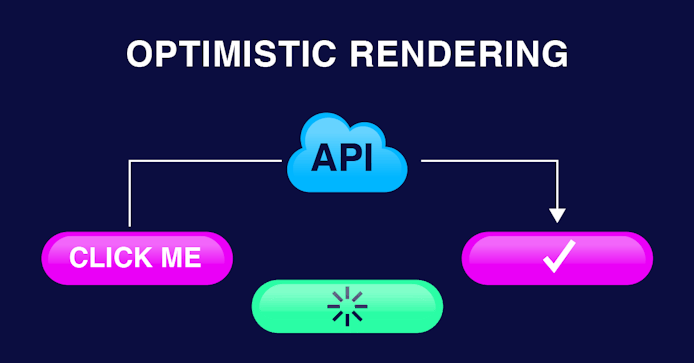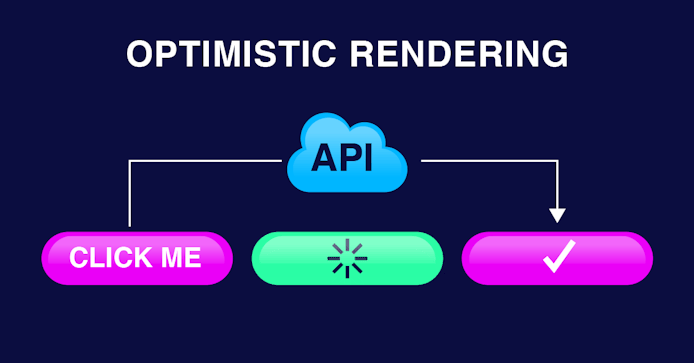
Let’s paint a picture using messaging applications as an example:
In many messaging apps, when you hit send on your message, it has to route from your device to a server, then on to the receiving device. At this point, we often see the message as being sent.
The problem is, this isn’t always true.
Many messaging applications use “optimistic rendering” to counteract real-time performance issues. This makes it look like a message was delivered when in reality, it could end up lost or stuck on the device they were sent from.
So, while optimistic rendering improves your immediate experience (letting you know your message was delivered), it can actually harm productivity and overall experience if that message wasn’t received in real-time.
So what are we talking about here?
What we are trying to make clear is that we are not facing a storage or compute problem when it comes to using real-time applications.
No.
What we are dealing with is a network problem.
It’s time that we understand and finally address this issue to provide a faster and more reliable real-time experience for users worldwide.
Global Latency Requires a Global Solution
To understand how to solve this network problem as it pertains to global latency, we must first look at the interactive profiles of global latency.
As mentioned above, developers don’t see use cases, request-response, or information flow as being distinct.
So, let’s break down each category that comprises the interactive profile of global latency to show why distinction matters when solving for this problem.
Folks connecting to e-commerce and social media networks
For these folks, data is processed using a web-centric request-response. This allows a lot of the data to be cached, which helps with speed and deliverability.
The problem is, this doesn’t work for real-time traffic.
For example, a lot of APIs are still web-centric but use always origin methods. So, you can’t cache a lot of those responses. They ultimately need to come back to a fixed location for everyone around the world.
Always origin methods
Similarly, some real-time applications, especially within the world of multiplayer gaming, rely on always origin but have been regionalized.
To put this in perspective, say you are playing Call of Duty within Europe. The always origin point for these players is Frankfurt, Germany.
While playing at the regional level, this is great.
It works.
However, if someone from outside Europe tries to play the game on that network, they are met with high ping times and frustratingly bad latency issues.
It makes the game unplayable and unenjoyable.
From a game publishing perspective, this isn’t what you want to see.
It limits your ability to scale the total addressable market for the game and limits revenue opportunities.
Using edge computing to solve latency issues
The limitations become especially problematic for those using edge computing to solve latency issues.
Edge computing works amazingly well if you only ever need to interact with people in your neighborhood.
But what happens when you want to expand outside of your neighborhood and interact with people across the world?
A whole mess of problems can occur, the most important impacting scalability and playability.
By now, you should be able to start seeing the bigger problem we are facing here.
We need to recalibrate our focus when it comes to how we build our networks. We need to go larger and have a more global perspective.
How Standard Measurements for Latency Fail to Capture the Needs of Real-Time
Can we say that we are making our best effort to optimize the internet for real-time traffic if we aren’t using methods of measurement that actually apply to this unique type of traffic?
The current methods we use to measure and “optimize” this traffic fall short in many areas.
Let’s briefly explore our current methods of measurement and why they do not help in solving the problem of global latency for real-time traffic.
Time to First Byte (TTFB)
When it comes to time to first byte measurement, consideration is only given to the first byte’s performance while all subsequent performance is omitted.
This type of measurement may work well for simple functions like browsing social media or connecting to an e-commerce site, but it fails to consider and capture real-time performance concerns.
Network Time Protocol (NTP)
Similar to how the standard model of physics fails when you reach the quantum level, network time protocol fails when measuring real-time traffic.
The standard model of physics observes various phenomena at low energy but ignores that accelerators are getting more and more powerful.
This leads to gaps in the ability to measure particles moving at the speed of light.
It’s the same issue we face when using NTP to measure real-time traffic.
Clock sync variance with NTP is likely somewhere between 100ms and 250ms.
This means that by the time a measurement is actually taken, it is already out of date and rendered useless for real-time performance measurement.
The bigger problem?
Some devices don’t sync to NTP at all.
With such a significant variance, measurement events using NTP are bound to be frustrating and inaccurate for real-time traffic.
Round-Trip Time (RTT)
Round-trip time would be a useful metric when measuring real-time traffic IF that round trip traffic were symmetrical.
Because real-time traffic is not symmetrical, it requires asymmetrical solutions and software that can detect and consolidate problems while they are occurring.
Let’s look at a practical example our team at Subspace recently worked on to understand what we are talking about fully:
The Subspace team was recently tasked with improving performance between Atlanta, Georgia, and Ashburn, Virginia (near Washington D.C.).
While working on this network, we saw extremely high ping times hitting 60ms.
While working on improving the performance of this network path, we discovered a variance that saw packets travelling at 13ms to Ashburn and 47ms back to Atlanta.
An asymmetrical roundtrip.
By isolating the trip from Ashburn to Atlanta and creating a solution to improve the return, we optimized roundtrip packet travel to 13ms each way.
This is the power of software that can detect and consolidate real-time traffic problems as they are happening.
Subspace Addresses the Root Problem
Our team at Subspace has been on a mission to make the internet not just “good enough”, but optimal for real-time traffic.
We optimize real-time traffic using our patented technology to synchronize users and ensure that all traffic paths are optimized globally.
By assessing network conditions at the sub-millisecond level, we do what is impossible for most network service providers, resulting in a better experience for end-users globally.
Rather than rely on humans to fix network problems, Subspace leverages software.
This allows our team to quickly and accurately make the appropriate network changes and learn from our results to improve real-time traffic before users even notice there is a problem.
Furthermore, our software allows our team to solve the challenge of network optimization for every major network path across the globe—a problem that until now has not been solved due to the overwhelming human input requirements.
It has been impractical.
Our patented proprietary IP allows our team to achieve what would otherwise require over 10,000 servers per continent.
What does this mean for you?
We do all the computation and sub-millisecond path optimization, so you don’t have to.
You simply integrate your real-time applications with our APIs with a few lines of code and focus on other critical areas of your business.
Subspace PacketAccelerator reduces latency and accelerates packets, helping to increase your users’ performance and decrease their stress. Subspace WebRTC-CDN allows you to run TURN globally without having to maintain servers around the world. SIPTeleport is a Global SIP Proxy for the lowest latency voice and video calls. And with RTPSpeed, we provide the highest quality voice and video steaming (via a global RTP proxy) the internet has ever seen.
Conclusion
“Good enough” is no longer good enough. Real-time applications require a different approach when solving for latency—a global approach. To solve the issues we are facing, we can’t only consider storage and computing as we have for decades. Instead, we need to incorporate and respect the network’s needs as we work to solve global latency problems.
Developers and providers need to approach global latency differently, with new solutions and a new set of better, more accurate metrics. As the demand for real-time applications grows, users expect instant synchronicity across the globe and near-perfect digital experiences. Meeting these expectations will require developers and providers to think differently and approach challenges from a lens of scalability and scope.
To read more about global latency and its impact in today’s real-time world, download this free whitepaper.


